# Rust 学习笔记
# 变量声明:
struct Struct{ | |
e:i32 | |
} | |
fn main() { | |
// 若不使用变量时,需要在变量名前面写一个下划线,表示该变量不会被使用,这样才不会报错 | |
// let mut _x = 5; | |
// _x = 6; | |
// println!("The value of x is: {}", _x); | |
//let (a,mut b):(bool,bool)=(true,false); | |
//println!("a is {:?},b is {:?}",a,b); | |
//b=true; | |
//assert_eq!(a,b);// 用于检查两个值是否相等。如果它们不相等,程序会 panic! 并终止运行 | |
let (a, b, c, d, e); | |
(a, b) = (1, 2); | |
//_ 代表匹配一个值,但是我们不关心具体的值是什么,因此没有使用一个变量名而是使用了 _ | |
[c, .., d, _] = [1, 2, 3, 4, 5]; | |
Struct { e, .. } = Struct { e: 5 }; | |
println!("a is {}, b is {}, c is {}, d is {}, e is {}", a, b, c, d, e); | |
assert_eq!([1, 2, 1, 4, 5], [a, b, c, d, e]); | |
// 常量: | |
const MAX_POINTS: u32 = 100_000; | |
println!("The value of MAX_POINTS is: {}", MAX_POINTS); | |
let space = " "; | |
println!("空格的数量是{}", space.len()); | |
let guess:i32 = "42".parse().expect("Not a number!"); | |
//or:let guess = "42".parse::<i32>().expect("Not a number!"); | |
} |
模式匹配: [c, .., d, _] = [1, 2, 3, 4, 5];
先是匹配..,先把后面的 d,_这两个匹配到后面数值的最后两个,然后在进行赋值
匹配中间任意长度的切片(但不绑定变量)
匹配最后一个元素(忽略)
结构体的模式匹配(解构赋值):
Struct { e, .. } = Struct { e: 5 };
这个操作就是匹配一个结构体,把他的 e 字段绑定到外部的变量 e,其他字段(..)忽略
这个实例就是将 e 这个变量赋值为 5
用这个时不需要进行声明这个变量:
等值于:
let tmp = Struct { e: 5 }; | |
e = tmp.e; |
# 数值类型:
# 整数类型:
rust 内置的整数类型

整形字面量可以用下表的形式书写:

fn main() { | |
let a:u8 = 255; | |
let b= a.wrapping_add(20); // 相当于加法,给溢出了 | |
println!("{}",b); //19 | |
} |
# 浮点型:
两种:f32 和 f64-- 默认
由于精度的原因,我们的 0.1+0.2 不会完全等于 0.3(类似于 python)

我们在 rust 可以用:
(0.1_f64 + 0.2 - 0.3).abs() < 0.00001 |
fn main() {
let abc: (f32, f32, f32) = (0.1, 0.2, 0.3);
let xyz: (f64, f64, f64) = (0.1, 0.2, 0.3);
println!("abc (f32)"); | |
println!(" 0.1 + 0.2: {:x}", (abc.0 + abc.1).to_bits()); | |
println!(" 0.3: {:x}", (abc.2).to_bits()); | |
println!(); | |
println!("xyz (f64)"); | |
println!(" 0.1 + 0.2: {:x}", (xyz.0 + xyz.1).to_bits()); | |
println!(" 0.3: {:x}", (xyz.2).to_bits()); | |
println!(); | |
assert!(abc.0 + abc.1 == abc.2); | |
assert!(xyz.0 + xyz.1 == xyz.2);} |
结果:
abc (f32)
0.1 + 0.2: 3e99999a
0.3: 3e99999a
xyz (f64)
0.1 + 0.2: 3fd3333333333334
0.3: 3fd3333333333333
thread 'main' panicked at main.rs:16:5:
assertion failed: xyz.0 + xyz.1 == xyz.2
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
对 f32 类型做加法时, 0.1 + 0.2 的结果是 3e99999a , 0.3 也是 3e99999a ,因此 f32 下的 0.1 + 0.2 == 0.3 通过测试,但是到了 f64 类型时,结果就不一样了,因为 f64 精度高很多,因此在小数点非常后面发生了一点微小的变化, 0.1 + 0.2 以 4 结尾,但是 0.3 以 3 结尾,这个细微区别导致 f64 下的测试失败了,并且抛出了异常。
# 运算:
+-*/ %(求余)
# 位运算:

fn main() { | |
// 无符号 8 位整数,二进制为 00000010 | |
let a: u8 = 2; // 也可以写 let a: u8 = 0b_0000_0010; | |
// 二进制为 00000011 | |
let b: u8 = 3; | |
// {:08b}:左高右低输出二进制 01,不足 8 位则高位补 0 | |
println!("a value is {:08b}", a); | |
println!("b value is {:08b}", b); | |
println!("(a & b) value is {:08b}", a & b); | |
println!("(a | b) value is {:08b}", a | b); | |
println!("(a ^ b) value is {:08b}", a ^ b); | |
println!("(!b) value is {:08b}", !b); | |
println!("(a << b) value is {:08b}", a << b); | |
println!("(a >> b) value is {:08b}", a >> b); | |
let mut a = a; | |
// 注意这些计算符除了!之外都可以加上 = 进行赋值 (因为!= 要用来判断不等于) | |
a <<= b; | |
println!("(a << b) value is {:08b}", a); | |
} |
位运算要用 u8,结果:
a value is 00000010
b value is 00000011
(a & b) value is 00000010
(a | b) value is 00000011
(a ^ b) value is 00000001
(!b) value is 11111100
(a << b) value is 00010000
(a >> b) value is 00000000
(a << b) value is 00010000
# 序列(***):
我们可以用 1..5 这个来生成 1-5 这几个连续数值,包括 5
若是不用包括这个 5,可以直接 1..5
for i in 1..=5{ | |
println!("{}",i); | |
} |
1
2
3
4
5
还能用于字符类型,源于他们的连续型(猜测应该是 ascii 的连续性)
# AS 完成类型转换:
fn main() { | |
let a = 3.1 as i8; | |
let b = 100_i8 as i32; | |
let c = 'a' as u8; // 将字符 'a' 转换为整数,97 | |
println!("{},{},{}",a,b,c) | |
} |
有理数和复数:
use num::complex::Complex; | |
fn main() { | |
let a = Complex { re: 2.1, im: -1.2 }; | |
let b = Complex::new(11.1, 22.2); | |
let result = a + b; | |
println!("{} + {}i", result.re, result.im) | |
} |
结果:
13.2 + 21i
# 字符,布尔,单元类型:
单元类型:
单元类型就是 () ,对,你没看错,就是 () ,唯一的值也是 () ,一些读者读到这里可能就不愿意了,你也太敷衍了吧,管这叫类型?
只能说,再不起眼的东西,都有其用途,在目前为止的学习过程中,大家已经看到过很多次 fn main() 函数的使用吧?那么这个函数返回什么呢?
没错, main 函数就返回这个单元类型 () ,你不能说 main 函数无返回值,因为没有返回值的函数在 Rust 中是有单独的定义的: 发散函数( diverge function ) ,顾名思义,无法收敛的函数。
例如常见的 println!() 的返回值也是单元类型 () 。
再比如,你可以用 () 作为 map 的值,表示我们不关注具体的值,只关注 key 。 这种用法和 Go 语言的 struct{} 类似,可以作为一个值用来占位,但是完全不占用任何内存。
# 语句与表达式:
表达式会进行求值,然后返回一个值。例如 5 + 6 ,在求值后,返回值 11 ,因此它就是一条表达式。
表达式可以成为语句的一部分,例如 let y = 6 中, 6 就是一个表达式,它在求值后返回一个值 6 (有些反直觉,但是确实是表达式)。
调用一个函数是表达式,因为会返回一个值,调用宏也是表达式,用花括号包裹最终返回一个值的语句块也是表达式,总之,能返回值,它就是表达式:
fn main(){ | |
let y ={let x =3;x+1}; | |
println!("The value o y is:{}",y); | |
} |
语句块:
{
let x =3;
x+1
}
这里的 x+1 就是返回的值
若在表达式里面加上;就是代表不会返回值
fn main() { | |
assert_eq!(ret_unit_type(), ()) | |
} | |
fn ret_unit_type() { | |
let x = 1; | |
//if 语句块也是一个表达式,因此可以用于赋值,也可以直接返回 | |
// 类似三元运算符,在 Rust 里我们可以这样写 | |
let y = if x % 2 == 1 { | |
"odd" | |
} else { | |
"even" | |
}; | |
// 或者写成一行 | |
let z = if x % 2 == 1 { "odd" } else { "even" }; | |
} |
# 函数:
例子:
fn add(i:i32,j:i32)->i32{ | |
i+j | |
} |

# 所有权与借用:
# 所有权:
所有的程序都必须和计算机内存打交道,如何从内存中申请空间来存放程序的运行内容,如何在不需要的时候释放这些空间,成了重中之重,也是所有编程语言设计的难点之一。在计算机语言不断演变过程中,出现了三种流派:
- 垃圾回收机制 (GC),在程序运行时不断寻找不再使用的内存,典型代表:Java、Go
- 手动管理内存的分配和释放,在程序中,通过函数调用的方式来申请和释放内存,典型代表:C++
- 通过所有权来管理内存,编译器在编译时会根据一系列规则进行检查
其中 Rust 选择了第三种,最妙的是,这种检查只发生在编译期,因此对于程序运行期,不会有任何性能上的损失。
由于所有权是一个新概念,因此读者需要花费一些时间来掌握它,一旦掌握,海阔天空任你飞跃,在本章,我们将通过 字符串 来引导讲解所有权的相关知识。
int* foo() { | |
int a; // 变量 a 的作用域开始 | |
a = 100; | |
char *c = "xyz"; // 变量 c 的作用域开始 | |
return &a; | |
} // 变量 a 和 c 的作用域结束 |
这段代码虽然可以编译通过,但是其实非常糟糕,变量 a 是在函数内进行的定义分配的内存,现在我返回这个的指针,但是我分配时在这个函数块里面,这样的话过了这个函数 a 就会被自动释放,这个 a 变量的指针会被释放无效,或是被其他的函数调用或局部变量覆盖,从而造成了 悬空指针(Dangling Pointer) 的问题。这是一个非常典型的内存安全问题,虽然编译可以通过,但是运行的时候会出现错误,很多编程语言都存在。
再来看变量 c , c 的值是常量字符串,存储于常量区,可能这个函数我们只调用了一次,也可能我们不再会使用这个字符串,但 "xyz" 只有当整个程序结束后系统才能回收这片内存。
所以内存安全问题,一直都是程序员非常头疼的问题,好在,在 Rust 中这些问题即将成为历史,因为 Rust 在编译的时候就可以帮助我们发现内存不安全的问题,那 Rust 如何做到这一点呢?
在正式进入主题前,先来一个预热知识。
# 栈与堆:
栈和堆的核心目标就是
为程序在运行时提供可供使用的内存空间。
# 栈:
(栈中的数据必须是占用已知且固定大小的内存空间)先进后出,加数据是进栈,移出数据叫出栈
# 堆:
(堆中的数据都是大小未知或者可能变化的数据)
当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的指针,该过程被称为在堆上分配内存,有时简称为 “分配”(allocating)。
接着该指针会被推入栈中中,因为指针的大小是一直且固定的,后续使用过程中可以通过这个指针访问堆来访问这指针对应的数据
# 性能区别:
在栈上分配内存比在堆上分配内存要快,因为入栈时操作系统无需进行函数调用(或更慢的系统调用)来分配新的空间,只需要将新数据放入栈顶即可。相比之下,在堆上分配内存则需要更多的工作,这是因为操作系统必须首先找到一块足够存放数据的内存空间,接着做一些记录为下一次分配做准备,如果当前进程分配的内存页不足时,还需要进行系统调用来申请更多内存。 因此,处理器在栈上分配数据会比在堆上分配数据更加高效。
# 所有权与堆栈
当你的代码调用一个函数时,传递给函数的参数(包括可能指向堆上数据的指针和函数的局部变量)依次被压入栈中,当函数调用结束时,这些值将被从栈中按照相反的顺序依次移除。
因为堆上的数据缺乏组织,因此跟踪这些数据何时分配和释放是非常重要的,否则堆上的数据将产生内存泄漏 —— 这些数据将永远无法被回收。这就是 Rust 所有权系统为我们提供的强大保障。
对于其他很多编程语言,你确实无需理解堆栈的原理,但是在 Rust 中,明白堆栈的原理,对于我们理解所有权的工作原理会有很大的帮助。
# 所有权原则:
规则:
1.rust中每一个值都被一个变量所拥有,该变量被称为值的所有者
2.一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
3.当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
例如字符串:
之前的语言都是直接给一个字符串值,但是不能改变了,这中叫做是被硬编码进程序里的字符串值(类型为 & str)
又两个缺点:
不能变,不是什么时候都是可以在编写代码时后就可以得知的
所以,rust 提供动态字符串类型:String, 该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小位置的文本
可以用下面的方法基于字符串字面量来创建 String 类型:
let s =String::from("hello"); |
:: 是一种调用操作符,这里表示调用 String 类型中的 from 关联函数,由于 String 类型存储在堆上,因此它是动态的,可以修改:
let mut s =String::from("hello ");
s.push_str(",world");
println!("{}",s);
用 push_str 函数就可以加进去了
# 变量绑定背后的数据交互:
let s1= String::from("hello");
let s2=s1;
String 类型是一个复杂类型,又存储在栈中的堆指针,字符串长度,字符串容量,其中堆指针是最重要的,容量是堆内存分配空间的大小,长度是目前已经使用的大小。
Rust 这样解决问题:当 s1 被赋予 s2 后,Rust 认为 s1 不再有效,因此也无需在 s1 离开作用域后 drop 任何东西,这就是把所有权从 s1 转移给了 s2 , s1 在被赋予 s2 后就马上失效了。
s1 的引用便会无效了
这样就解决了我们之前的问题, s1 不再指向任何数据,只有 s2 是有效的,当 s2 离开作用域,它就会释放内存。 相信此刻,你应该明白了,为什么 Rust 称呼 let a = b 为变量绑定了吧?
# 引用与解引用
# 不可变引用:
fn main() { | |
let s1 = String::from("hello"); | |
let len = calculate_length(&s1); | |
println!("The length of '{}' is {}.", s1, len); | |
} | |
fn calculate_length(s: &String) -> usize { | |
s.len() | |
} |
这个函数fn calculate_length(s: &String) -> usize {
s.len()
}我没有对这个函数进行任何操作,所以什么也不会发生
但是有时候我们有需要对引用进来的值进行操作
这时候就要用 mut 来可变一下了
# 可变引用:
fn main() { | |
let mut s = String::from("hello"); | |
change(&mut s); | |
} | |
fn change(some_string: &mut String) { | |
some_string.push_str(", world"); | |
} |
# 这两者的区别与联系:
1.可变引用只能在一个作用域里面有一个
2.可变引用与不可变引用只能有一个
3.只有不可变引用时,可以有多个不可变引用
# 悬垂引用 (Dangling References)
悬垂引用也叫做悬垂指针,意思为指针指向某个值后,这个值被释放掉了,而指针仍然存在,其指向的内存可能不存在任何值或已被其它变量重新使用。在 Rust 中编译器可以确保引用永远也不会变成悬垂状态:当你获取数据的引用后,编译器可以确保数据不会在引用结束前被释放,要想释放数据,必须先停止其引用的使用。
让我们尝试创建一个悬垂引用,Rust 会抛出一个编译时错误:
fn main() { | |
let reference_to_nothing = dangle(); | |
} | |
fn dangle() -> &String { | |
let s = String::from("hello"); | |
&s | |
} |
这里是错误:
error[E0106]: missing lifetime specifier | |
--> src/main.rs:5:16 | |
| | |
5 | fn dangle() -> &String { | |
| ^ expected named lifetime parameter | |
| | |
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from | |
help: consider using the `'static` lifetime | |
| | |
5 | fn dangle() -> &'static String { | |
| ~~~~~~~~ |
错误信息引用了一个我们还未介绍的功能:生命周期 (lifetimes)。不过,即使你不理解生命周期,也可以通过错误信息知道这段代码错误的关键信息:
this function's return type contains a borrowed value, but there is no value for it to be borrowed from. | |
该函数返回了一个借用的值,但是已经找不到它所借用值的来源 |
仔细看看 dangle 代码的每一步到底发生了什么:
fn dangle() -> &String { //dangle 返回一个字符串的引用 | |
let s = String::from("hello"); //s 是一个新字符串 | |
&s // 返回字符串 s 的引用 | |
} // 这里 s 离开作用域并被丢弃。其内存被释放。 | |
// 危险! |
因为 s 是在 dangle 函数内创建的,当 dangle 的代码执行完毕后, s 将被释放,但是此时我们又尝试去返回它的引用。这意味着这个引用会指向一个无效的 String ,这可不对!
其中一个很好的解决方法是直接返回 String :
fn no_dangle() -> String { | |
let s = String::from("hello"); | |
s | |
} |
这样就没有任何错误了,最终 String 的 所有权被转移给外面的调用者。
# 借用规则总结
-
总的来说,借用规则如下: - 同一时刻,你只能拥有要么一个可变引用,要么任意多个不可变引用 - 引用必须总是有效的
# 复合类型:
# 字符串与切片:
# 字符串:
&str 是一个不可变引用(字符串字面量)
String 是可以用来可变引用的
# 切片:
对字符串而言,切片就是对 String 类型中某一部分的引用
let s = String::from("hello world"); | |
let hello = &s[0..5]; | |
let world = &s[6..11]; |
hello 就是从 0 索引开始,到索引 5 之前截止(0-4,不包括)
world 同理

切片想要包含 String 最后一个字节:
let s = String::from("hello"); | |
let len = s.len(); | |
let slice = &s[4..len]; | |
let slice = &s[4..]; |
在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
let s = "中国人"; | |
let a = &s[0..2]; | |
println!("{}",a); |
什么是字符串:字符组成的连续集合
Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的 (1 - 4) Rust 在语言级别,只有一种字符串类型: str ,它通常是以引用类型出现 &str ,也就是上文提到的字符串切片。虽然语言级别只有上述的 str 类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是 String 类型
str 类型是硬编码进可执行文件,也无法被修改,但是 String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
除了 String 类型的字符串,Rust 的标准库还提供了其他类型的字符串,例如 OsString , OsStr , CsString 和 CsStr 等,注意到这些名字都以 String 或者 Str 结尾了吗?它们分别对应的是具有所有权和被借用的变量。
# String 与 & str 的转换:
在之前的代码中,已经见到好几种从 &str 类型生成 String 类型的操作:
String::from("hello,world")"hello,world".to_string()
那么如何将 String 类型转为 &str 类型呢?答案很简单,取引用即可:
fn main() { | |
let s = String::from("hello,world!"); | |
say_hello(&s); | |
say_hello(&s[..]); | |
say_hello(s.as_str()); | |
} | |
fn say_hello(s: &str) { | |
println!("{}",s); | |
} |
实际上这种灵活用法是因为 deref 隐式强制转换,具体我们会在 Deref 特征进行详细讲解。
# 字符串索引
在其它语言中,使用索引的方式访问字符串的某个字符或者子串是很正常的行为,但是在 Rust 中就会报错:
let s1 = String::from("hello"); | |
let h = s1[0]; |
该代码会产生如下错误:
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`
# 深入字符串内部
字符串的底层的数据存储格式实际上是 [ u8 ],一个字节数组。对于 let hello = String::from("Hola"); 这行代码来说, Hola 的长度是 4 个字节,因为 "Hola" 中的每个字母在 UTF-8 编码中仅占用 1 个字节,但是对于下面的代码呢?
let hello = String::from("中国人"); |
如果问你该字符串多长,你可能会说 3 ,但是实际上是 9 个字节的长度,因为大部分常用汉字在 UTF-8 中的长度是 3 个字节,因此这种情况下对 hello 进行索引,访问 &hello[0] 没有任何意义,因为你取不到 中 这个字符,而是取到了这个字符三个字节中的第一个字节,这是一个非常奇怪而且难以理解的返回值。
# 字符串的不同表现形式
现在看一下用梵文写的字符串 “नमस्ते” , 它底层的字节数组如下形式:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164, | |
224, 165, 135] |
长度是 18 个字节,这也是计算机最终存储该字符串的形式。如果从字符的形式去看,则是:
['न', 'म', 'स', '्', 'त', 'े'] |
但是这种形式下,第四和六两个字母根本就不存在,没有任何意义,接着再从字母串的形式去看:
["न", "म", "स्", "ते"] |
所以,可以看出来 Rust 提供了不同的字符串展现方式,这样程序可以挑选自己想要的方式去使用,而无需去管字符串从人类语言角度看长什么样。
还有一个原因导致了 Rust 不允许去索引字符串:因为索引操作,我们总是期望它的性能表现是 O (1),然而对于 String 类型来说,无法保证这一点,因为 Rust 可能需要从 0 开始去遍历字符串来定位合法的字符。
# 字符串切片
前文提到过,字符串切片是非常危险的操作,因为切片的索引是通过字节来进行,但是字符串又是 UTF-8 编码,因此你无法保证索引的字节刚好落在字符的边界上,例如:
let hello = "中国人"; | |
let s = &hello[0..2]; |
运行上面的程序,会直接造成崩溃:
thread 'main' panicked at 'byte index 2 is not a char boundary; it is inside '中' (bytes 0..3) of `中国人`', src/main.rs:4:14
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
这里提示的很清楚,我们索引的字节落在了 中 字符的内部,这种返回没有任何意义。
因此在通过索引区间来访问字符串时,需要格外的小心,一不注意,就会导致你程序的崩溃!
# 字符串操作(***):
# 追加 (Push)
在字符串尾部可以使用 push() 方法追加字符 char ,也可以使用 push_str() 方法追加字符串字面量。这两个方法都是在原有的字符串上追加,并不会返回新的字符串。由于字符串追加操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
fn main() { | |
let mut s = String::from("Hello "); | |
s.push_str("rust"); | |
println!("追加字符串 push_str() -> {}", s); | |
s.push('!'); | |
println!("追加字符 push() -> {}", s); | |
} |
代码运行结果:
追加字符串 push_str() -> Hello rust
追加字符 push() -> Hello rust!
# 插入 (Insert)
可以使用 insert() 方法插入单个字符 char ,也可以使用 insert_str() 方法插入字符串字面量,与 push() 方法不同,这俩方法需要传入两个参数,第一个参数是字符(串)插入位置的索引,第二个参数是要插入的字符(串),索引从 0 开始计数,如果越界则会发生错误。由于字符串插入操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
fn main() { | |
let mut s = String::from("Hello rust!"); | |
s.insert(5, ','); | |
println!("插入字符 insert() -> {}", s); | |
s.insert_str(6, " I like"); | |
println!("插入字符串 insert_str() -> {}", s); | |
} |
代码运行结果:
插入字符 insert() -> Hello, rust!
插入字符串 insert_str() -> Hello, I like rust!
# 替换 (Replace)
如果想要把字符串中的某个字符串替换成其它的字符串,那可以使用 replace() 方法。与替换有关的方法有三个。
1、 replace
该方法可适用于 String 和 &str 类型。 replace() 方法接收两个参数,第一个参数是要被替换的字符串,第二个参数是新的字符串。该方法会替换所有匹配到的字符串。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
fn main() { | |
let string_replace = String::from("I like rust. Learning rust is my favorite!"); | |
let new_string_replace = string_replace.replace("rust", "RUST"); | |
dbg!(new_string_replace); | |
} |
代码运行结果:
new_string_replace = "I like RUST. Learning RUST is my favorite!"
2、 replacen
该方法可适用于 String 和 &str 类型。 replacen() 方法接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
fn main() { | |
let string_replace = "I like rust. Learning rust is my favorite!"; | |
let new_string_replacen = string_replace.replacen("rust", "RUST", 1); | |
dbg!(new_string_replacen); | |
} |
代码运行结果:
new_string_replacen = "I like RUST. Learning rust is my favorite!"
3、 replace_range
该方法仅适用于 String 类型。 replace_range 接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用 mut 关键字修饰。
示例代码如下:
fn main() { | |
let mut string_replace_range = String::from("I like rust!"); | |
string_replace_range.replace_range(7..8, "R"); | |
dbg!(string_replace_range); | |
} |
代码运行结果:
string_replace_range = "I like Rust!"
# 删除 (Delete)
与字符串删除相关的方法有 4 个,它们分别是 pop() , remove() , truncate() , clear() 。这四个方法仅适用于 String 类型。
1、 pop —— 删除并返回字符串的最后一个字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是一个 Option 类型,如果字符串为空,则返回 None 。
示例代码如下:
fn main() { | |
let mut string_pop = String::from("rust pop 中文!"); | |
let p1 = string_pop.pop(); | |
let p2 = string_pop.pop(); | |
dbg!(p1); | |
dbg!(p2); | |
dbg!(string_pop); | |
} |
代码运行结果:
p1 = Some(
'!',
)
p2 = Some(
'文',
)
string_pop = "rust pop 中"
2、 remove —— 删除并返回字符串中指定位置的字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,只接收一个参数,表示该字符起始索引位置。 remove() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
fn main() { | |
let mut string_remove = String::from("测试remove方法"); | |
println!( | |
"string_remove 占 {} 个字节", | |
std::mem::size_of_val(string_remove.as_str()) | |
); | |
// 删除第一个汉字 | |
string_remove.remove(0); | |
// 下面代码会发生错误 | |
// string_remove.remove(1); | |
// 直接删除第二个汉字 | |
// string_remove.remove(3); | |
dbg!(string_remove); | |
} |
代码运行结果:
string_remove 占 18 个字节
string_remove = "试remove方法"
3、 truncate —— 删除字符串中从指定位置开始到结尾的全部字符
该方法是直接操作原来的字符串。无返回值。该方法 truncate() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
fn main() { | |
let mut string_truncate = String::from("测试truncate"); | |
string_truncate.truncate(3); | |
dbg!(string_truncate); | |
} |
代码运行结果:
string_truncate = "测"
4、 clear —— 清空字符串
该方法是直接操作原来的字符串。调用后,删除字符串中的所有字符,相当于 truncate() 方法参数为 0 的时候。
示例代码如下:
fn main() { | |
let mut string_clear = String::from("string clear"); | |
string_clear.clear(); | |
dbg!(string_clear); | |
} |
代码运行结果:
string_clear = ""
# 连接 (Concatenate)
1、使用 + 或者 += 连接字符串
使用 + 或者 += 连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用 + 的操作符时,相当于调用了 std::string 标准库中的 add() 方法,这里 add() 方法的第二个参数是一个引用的类型。因此我们在使用 + 时, 必须传递切片引用类型。不能直接传递 String 类型。 + 是返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰。
示例代码如下:
fn main() { | |
let string_append = String::from("hello "); | |
let string_rust = String::from("rust"); | |
// &string_rust 会自动解引用为 & amp;str | |
let result = string_append + &string_rust; | |
let mut result = result + "!"; // `result +"!"`中的`result` 是不可变的 | |
result += "!!!"; | |
println!("连接字符串 + -> {}", result); | |
} |
代码运行结果:
连接字符串 + -> hello rust!!!!
add() 方法的定义:
fn add(self, s: &str) -> String |
因为该方法涉及到更复杂的特征功能,因此我们这里简单说明下:
fn main() { | |
let s1 = String::from("hello,"); | |
let s2 = String::from("world!"); | |
// 在下句中,s1 的所有权被转移走了,因此后面不能再使用 s1 | |
let s3 = s1 + &s2; | |
assert_eq!(s3,"hello,world!"); | |
// 下面的语句如果去掉注释,就会报错 | |
// println!("{}",s1); | |
} |
self 是 String 类型的字符串 s1 ,该函数说明,只能将 &str 类型的字符串切片添加到 String 类型的 s1 上,然后返回一个新的 String 类型,所以 let s3 = s1 + &s2; 就很好解释了,将 String 类型的 s1 与 &str 类型的 s2 进行相加,最终得到 String 类型的 s3 。
由此可推,以下代码也是合法的:
let s1 = String::from("tic"); | |
let s2 = String::from("tac"); | |
let s3 = String::from("toe"); | |
// String = String + &str + &str + &str + &str | |
let s = s1 + "-" + &s2 + "-" + &s3; |
String + &str 返回一个 String ,然后再继续跟一个 &str 进行 + 操作,返回一个 String 类型,不断循环,最终生成一个 s ,也是 String 类型。
s1 这个变量通过调用 add() 方法后,所有权被转移到 add() 方法里面, add() 方法调用后就被释放了,同时 s1 也被释放了。再使用 s1 就会发生错误。这里涉及到所有权转移(Move)的相关知识。
2、使用 format! 连接字符串
format! 这种方式适用于 String 和 &str 。 format! 的用法与 print! 的用法类似,详见格式化输出。
示例代码如下:
fn main() { | |
let s1 = "hello"; | |
let s2 = String::from("rust"); | |
let s = format!("{} {}!", s1, s2); | |
println!("{}", s); | |
} |
代码运行结果:
hello rust!
# 字符串转义:
我们可以通过转义的方式 \ 输出 ASCII 和 Unicode 字符。
fn main() { | |
// 通过 \ + 字符的十六进制表示,转义输出一个字符 | |
let byte_escape = "I'm writing \x52\x75\x73\x74!"; | |
println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape); | |
// \u 可以输出一个 unicode 字符 | |
let unicode_codepoint = "\u{211D}"; | |
let character_name = "\"DOUBLE-STRUCK CAPITAL R\""; | |
println!( | |
"Unicode character {} (U+211D) is called {}", | |
unicode_codepoint, character_name | |
); | |
// 换行了也会保持之前的字符串格式 | |
// 使用 \ 忽略换行符 | |
let long_string = "String literals | |
can span multiple lines. | |
The linebreak and indentation here ->\ | |
<- can be escaped too!"; | |
println!("{}", long_string); | |
} |
在 \ 加上一个 \ 转义这个就好了
fn main() { | |
println!("{}", "hello \\x52\\x75\\x73\\x74"); | |
let raw_str = r"Escapes don't work here: \x3F \u{211D}"; | |
println!("{}", raw_str); | |
// 如果字符串包含双引号,可以在开头和结尾加 # | |
let quotes = r#"And then I said: "There is no escape!""#; | |
println!("{}", quotes); | |
// 如果字符串中包含 # 号,可以在开头和结尾加多个 # 号,最多加 255 个,只需保证与字符串中连续 # 号的个数不超过开头和结尾的 # 号的个数即可 | |
let longer_delimiter = r###"A string with "# in it. And even "##!"###; | |
println!("{}", longer_delimiter); | |
} |
操作 UTF-8 字符串
前文提到了几种使用 UTF-8 字符串的方式,下面来一一说明。
# 字符
如果你想要以 Unicode 字符的方式遍历字符串,最好的办法是使用 chars 方法,例如:
for c in "中国人".chars() { | |
println!("{}", c); | |
} |
输出如下
中
国
人
# 字节
这种方式是返回字符串的底层字节数组表现形式:
for b in "中国人".bytes() { | |
println!("{}", b); | |
} |
输出如下:
228
184
173
229
155
189
228
186
186
# 获取子串
想要准确的从 UTF-8 字符串中获取子串是较为复杂的事情,例如想要从 holla中国人नमस्ते 这种变长的字符串中取出某一个子串,使用标准库你是做不到的。 你需要在 crates.io 上搜索 utf8 来寻找想要的功能。
可以考虑尝试下这个库:utf8_slice。
# 字符串深度剖析
那么问题来了,为啥 String 可变,而字符串字面值 str 却不可以?
就字符串字面值来说,我们在编译时就知道其内容,最终字面值文本被直接硬编码进可执行文件中,这使得字符串字面值快速且高效,这主要得益于字符串字面值的不可变性。不幸的是,我们不能为了获得这种性能,而把每一个在编译时大小未知的文本都放进内存中(你也做不到!),因为有的字符串是在程序运行的过程中动态生成的。
对于 String 类型,为了支持一个可变、可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容,这些都是在程序运行时完成的:
- 首先向操作系统请求内存来存放
String对象 - 在使用完成后,将内存释放,归还给操作系统
其中第一部分由 String::from 完成,它创建了一个全新的 String 。
重点来了,到了第二部分,就是百家齐放的环节,在有垃圾回收 GC 的语言中,GC 来负责标记并清除这些不再使用的内存对象,这个过程都是自动完成,无需开发者关心,非常简单好用;但是在无 GC 的语言中,需要开发者手动去释放这些内存对象,就像创建对象需要通过编写代码来完成一样,未能正确释放对象造成的后果简直不可估量。
对于 Rust 而言,安全和性能是写到骨子里的核心特性,如果使用 GC,那么会牺牲性能;如果使用手动管理内存,那么会牺牲安全,这该怎么办?为此,Rust 的开发者想出了一个无比惊艳的办法:变量在离开作用域后,就自动释放其占用的内存:
{ | |
let s = String::from("hello"); // 从此处起,s 是有效的 | |
// 使用 s | |
} // 此作用域已结束, | |
//s 不再有效,内存被释放 |
与其它系统编程语言的 free 函数相同,Rust 也提供了一个释放内存的函数: drop ,但是不同的是,其它语言要手动调用 free 来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用 drop 函数:上面代码中,Rust 在结尾的 } 处自动调用 drop 。
其实,在 C++ 中,也有这种概念:Resource Acquisition Is Initialization (RAII)。如果你使用过 RAII 模式的话应该对 Rust 的
drop函数并不陌生。
这个模式对编写 Rust 代码的方式有着深远的影响,在后面章节我们会进行更深入的介绍。
# 元组:
复合类型:
# 语法
可以通过一下用法创建元组:
fn main(){ | |
let tup:(i32,f64,u8)=(500,6.4,11); | |
} |
# 模式匹配:
fn main(){ | |
let tup=(600,5.4,2); | |
let(x,y,z)=tup; | |
println!("the value of y is {}",y); | |
} |
上述代码首先创建一个元组,然后将其绑定到 tup 上,接着使用 let (x, y, z) = tup; 来完成一次模式匹配,因为元组是 (n1, n2, n3) 形式的,因此我们用一模一样的 (x, y, z) 形式来进行匹配,元组中对应的值会绑定到变量 x , y , z 上。这就是解构:用同样的形式把一个复杂对象中的值匹配出来。
# 用。访问元组
fn main() { | |
let x: (i32, f64, u8) = (500, 6.4, 1); | |
let five_hundred = x.0; | |
let six_point_four = x.1; | |
let one = x.2; | |
} |
索引从 0 开始
使用实例:
fn main() { | |
let s1 = String::from("hello"); | |
let (s2, len) = calculate_length(s1); | |
println!("The length of '{}' is {}.", s2, len); | |
} | |
fn calculate_length(s: String) -> (String, usize) { | |
let length = s.len(); //len () 返回字符串的长度 | |
(s, length) | |
} |
# 结构体
# 语法:
中间的不是用;分隔,而是用,分割
struct User { | |
active: bool, | |
username: String, | |
email: String, | |
sign_in_count: u64, | |
} |
创建实例:
let user1 = User { | |
email: String::from("someone@example.com"), | |
username: String::from("someusername123"), | |
active: true, | |
sign_in_count: 1, | |
}; |
有几点值得注意:
- 初始化实例时,每个字段都需要进行初始化
- 初始化时的字段顺序不需要和结构体定义时的顺序一致
# 用。访问结构体字段:
let mut user1 = User { | |
email: String::from("someone@example.com"), | |
username: String::from("someusername123"), | |
active: true, | |
sign_in_count: 1, | |
}; | |
user1.email = String::from("anotheremail@example.com"); |
# 简化结构体创建:
fn build_user(email:String ,username:String)->User{ | |
User{ | |
email:email, | |
username:username, | |
active:true, | |
sign_in_count:1, | |
} | |
} |
它接收两个字符串参数: email 和 username ,然后使用它们来创建一个 User 结构体,并且返回。可以注意到这两行: email: email 和 username: username ,非常的扎眼,因为实在有些啰嗦,如果你从 TypeScript 过来,肯定会鄙视 Rust 一番,不过好在,它也不是无可救药:
fn build_user(email:String,username:String)->User{ | |
User{ | |
email, | |
username, | |
active:true, | |
sign_in_count:1, | |
} | |
} |
# 结构体更新语法:
用已有的 user1 来构建 user2:
let user2=User{ | |
active:user1.active, | |
username:user1.username, | |
email:String::from("dwqdqd@example.com"), | |
sign_in_count:user1.sign_in_count, | |
}; |
rust 给的更新语法:
let user2=User{ | |
email:String::from("dwqdqd@example.com"); | |
..user1 | |
}; |
因为 user2 仅仅在 email 上与 user1 不同,因此我们只需要对 email 进行赋值,剩下的通过结构体更新语法 ..user1 即可完成。
.. 语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。
# 需要注意的是 ..user1 必须在结构体的尾部使用。
结构体更新语法跟赋值语句 `=` 非常相像,因此在上面代码中,`user1` 的部分字段所有权被转移到 `user2` 中:`username` 字段发生了所有权转移,作为结果,`user1` 无法再被使用。
聪明的读者肯定要发问了:明明有三个字段进行了自动赋值,为何只有 `username` 发生了所有权转移?
仔细回想一下[所有权](https://course.rs/basic/ownership/ownership.html#拷贝浅拷贝)那一节的内容,我们提到了 `Copy` 特征:实现了 `Copy` 特征的类型无需所有权转移,可以直接在赋值时进行 数据拷贝,其中 `bool` 和 `u64` 类型就实现了 `Copy` 特征,因此 `active` 和 `sign_in_count` 字段在赋值给 `user2` 时,仅仅发生了拷贝,而不是所有权转移。
值得注意的是:`username` 所有权被转移给了 `user2`,导致了 `user1` 无法再被使用,但是并不代表 `user1` 内部的其它字段不能被继续使用,例如:
let user1 = User { | |
email: String::from("someone@example.com"), | |
username: String::from("someusername123"), | |
active: true, | |
sign_in_count: 1, | |
}; | |
let user2 = User { | |
active: user1.active, | |
username: user1.username, | |
email: String::from("another@example.com"), | |
sign_in_count: user1.sign_in_count, | |
}; | |
println!("{}", user1.active); | |
// 下面这行会报错 | |
println!("{:?}", user1); |
# 结构体的内存排列:
#[derive(Debug)] | |
struct File { | |
name: String, | |
data: Vec<u8>, | |
} | |
fn main() { | |
let f1 = File { | |
name: String::from("f1.txt"), | |
data: Vec::new(), | |
}; | |
let f1_name = &f1.name; | |
let f1_length = &f1.data.len(); | |
println!("{:?}", f1); | |
println!("{} is {} bytes long", f1_name, f1_length); | |
} |
file 结构体在内存中的排列如下图表示:

这个图清晰的看出 File 结构体两个字符 name 和 data 分别拥有两个 [u8] 数组的所有权(Stringl 欸行的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型
把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
# 元组结构体:
结构体必须有名称,但是结构体的字段可以没有这个名称,这种结构体很想元组,所以称为元组结构体,例如:
struct Color(i32,i32,i32); | |
struct Point(i32,i32,i32); | |
let black=Color(0,0,0); | |
let origin=Point(0,0,0); |
元组结构体在你希望有一个整体名称,但是又不关心里面字段的名称时将非常有用。例如上面的 Point 元组结构体,众所周知 3D 点是 (x, y, z) 形式的坐标点,因此我们无需再为内部的字段逐一命名为: x , y , z 。
# 单元结构体:
还记得之前讲过的基本没啥用的单元类型吧?单元结构体就跟它很像,没有任何字段和属性,但是好在,它还挺有用。
如果你定义一个类型,但是不关心该类型的内容,只关心它的行为时,就可以使用 单元结构体 :
struct AlwaysEqual; | |
let subject = AlwaysEqual; | |
// 我们不关心 AlwaysEqual 的字段数据,只关心它的行为,因此将它声明为单元结构体,然后再为它实现某个特征 | |
impl SomeTrait for AlwaysEqual { | |
} |
使用 #[derive (Debug)] 来打印结构体的信息
结构体没有实现 Display 特征,主要原因是由于结构体的复杂性(结构名,子成员的名字,值,所有权归属不知道要输出哪一些),所以用 {} 行不通
我们可以用 {:?} 来进行打印,但是会报错,
error[E0277]: `Rectangle` doesn't implement `Debug`
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
显示需要添加 #[derive (Debug)] 这条语句
因为,rust 不会为我们实现 Debug,为了实现,我们有两条方式进行选择:
手动实现
使用derive派生实现
后者简单得多,但是也有限制。如下使用就行:
#[derive(Debug)] | |
struct Rectangle { | |
width: u32, | |
height: u32, | |
} | |
fn main() { | |
let rect1 = Rectangle { | |
width: 30, | |
height: 50, | |
}; | |
println!("rect1 is {:?}", rect1); | |
} |
输出:
$ cargo run
rect1 is Rectangle { width: 30, height: 50 }
我们还可以用 dbg! 来打印
dbg! 输出到标准错误输出 stderr,而 println! 输出到标准输出 stdout。
#[derive(Debug)] | |
struct Rectangle { | |
width: u32, | |
height: u32, | |
} | |
fn main() { | |
let scale = 2; | |
let rect1 = Rectangle { | |
width: dbg!(30 * scale), | |
height: 50, | |
}; | |
dbg!(&rect1); | |
} |
[4.rs:10:16] 30 * scale = 60
[4.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
这下就全都有了
# 枚举
# 枚举:
例子:
枚举 (enum 或 enumeration) 允许你通过列举可能的成员来定义一个枚举类型,例如扑克牌花色:
enum PokerSuit{ | |
Clubs, | |
Spades, | |
Diamonds, | |
Hearts, | |
} |
枚举类型是一个类型,它会包含所有可能的枚举成员,而枚举值是该类型中的具体某个成员的实例。
# 枚举值:
创建枚举类型的两个成员实例:
let heart=PokerSuit::Hearts; | |
let diamond=PokerSuit::Diamonds; |
我们通过::操作符来访问 PokerSuit 下的具体成员,从代码可以清晰的看出,heart 和 diamond 都是 PokerSuit 枚举类型的,接着可以定义一个函数来使用他们:
#[derive(Debug)] | |
enum PokerSuit { | |
Clubs, | |
Spades, | |
Diamonds, | |
Hearts, | |
} | |
fn main() { | |
let heart = PokerSuit::Hearts; | |
let diamond = PokerSuit::Diamonds; | |
print_suit(heart); | |
print_suit(diamond); | |
} | |
fn print_suit(card: PokerSuit) { | |
// 需要在定义 enum PokerSuit 的上面添加上 #[derive (Debug)],否则会报 card 没有实现 Debug | |
println!("{:?}",card); | |
} |
print_suit 函数的参数类型是 PokerSuit ,因此我们可以把 heart 和 diamond 传给它,虽然 heart 是基于 PokerSuit 下的 Hearts 成员实例化的,但是它是货真价实的 PokerSuit 枚举类型。
接下来,我们想让扑克牌变得更加实用,那么需要给每张牌赋予一个值: A (1)- K (13),这样再加上花色,就是一张真实的扑克牌了,例如红心 A。
目前来说,枚举值还不能带有值,因此先用结构体来实现:
enum PokerSuit { | |
Clubs, | |
Spades, | |
Diamonds, | |
Hearts, | |
} | |
struct PokerCard { | |
suit: PokerSuit, | |
value: u8 | |
} | |
fn main() { | |
let c1 = PokerCard { | |
suit: PokerSuit::Clubs, | |
value: 1, | |
}; | |
let c2 = PokerCard { | |
suit: PokerSuit::Diamonds, | |
value: 12, | |
}; | |
} |
还有更简单的写法:
enum PokerCard { | |
Clubs(u8), | |
Spades(u8), | |
Diamonds(u8), | |
Hearts(u8), | |
} | |
fn main() { | |
let c1 = PokerCard::Spades(5); | |
let c2 = PokerCard::Diamonds(13); | |
} |
再复杂一点:
struct Ipv4Addr { | |
// --snip-- | |
} | |
struct Ipv6Addr { | |
// --snip-- | |
} | |
enum IpAddr { | |
V4(Ipv4Addr), | |
V6(Ipv6Addr), | |
} |
这里面就是 Ipv4Addr,Ipv6Addr 之类的结构体来定义两种不同的 IP 数据。
这样证明:任何类型的数据都可以放入枚举成员中
增加一些挑战?先看以下代码:
enum Message { | |
Quit, | |
Move { x: i32, y: i32 }, | |
Write(String), | |
ChangeColor(i32, i32, i32), | |
} | |
fn main() { | |
let m1 = Message::Quit; | |
let m2 = Message::Move{x:1,y:1}; | |
let m3 = Message::ChangeColor(255,255,0); | |
} |
该枚举类型代表一条消息,它包含四个不同的成员:
Quit没有任何关联数据Move包含一个匿名结构体Write包含一个String字符串ChangeColor包含三个i32
当然,我们也可以用结构体的方式来定义这些消息:
struct QuitMessage; // 单元结构体 | |
struct MoveMessage { | |
x: i32, | |
y: i32, | |
} | |
struct WriteMessage(String); // 元组结构体 | |
struct ChangeColorMessage(i32, i32, i32); // 元组结构体 |
由于每个结构体都有自己的类型,因此我们无法在需要同一类型的地方进行使用,例如某个函数它的功能是接受消息并进行发送,那么用枚举的方式,就可以接收不同的消息,但是用结构体,该函数无法接受 4 个不同的结构体作为参数。
而且从代码规范角度来看,枚举的实现更简洁,代码内聚性更强,不像结构体的实现,分散在各个地方。
# 同一化类型:
最后,再用一个实际项目中的简化片段,来结束枚举类型的语法学习。
例如我们有一个 WEB 服务,需要接受用户的长连接,假设连接有两种: TcpStream 和 TlsStream ,但是我们希望对这两个连接的处理流程相同,也就是用同一个函数来处理这两个连接,代码如下:
fn new (stream: TcpStream) { | |
let mut s = stream; | |
if tls { | |
s = negotiate_tls(stream) | |
} | |
//websocket 是一个 WebSocket<TcpStream > 或者 | |
// WebSocket<native_tls::TlsStream<TcpStream>> 类型 | |
websocket = WebSocket::from_raw_socket( | |
s, ......) | |
} |
此时,枚举类型就能帮上大忙:
enum Websocket { | |
Tcp(Websocket<TcpStream>), | |
Tls(Websocket<native_tls::TlsStream<TcpStream>>), | |
} |
# option 枚举用于处理空值:
在其它编程语言中,往往都有一个 null 关键字,该关键字用于表明一个变量当前的值为空(不是零值,例如整型的零值是 0),也就是不存在值。当你对这些 null 进行操作时,例如调用一个方法,就会直接抛出 null 异常,导致程序的崩溃,因此我们在编程时需要格外的小心去处理这些 null 空值。
# Rust 的做法 —— Option<T>
Rust 直接去掉了 null ,用 Option<T> 这个枚举类型来表示 “可能有值,也可能没值” 的情况。
enum Option<T> { | |
Some(T), // 代表有值 | |
None, // 代表没有值 | |
} |
Some(T)代表有值,比如Some(5)就表示5这个数。None代表没有值,相当于null,但它是Option<T>类型的一部分,不能直接使用。
Rust 这样设计的好处是:你必须显式处理可能的空值,防止程序出错!
# 例子:定义 Option<T> 变量
let some_number = Some(5); | |
let some_string = Some("Hello"); | |
let absent_number: Option<i32> = None; // 需要指定类型 |
如果是 None ,Rust 需要知道 Option<T> 的 T 是什么类型,比如 Option<i32> ,否则它不知道 None 代表什么类型。
# 为什么 Option<T> 比 null 好?
因为 Option<T> 和 T 是不同的类型,Rust 不允许直接把 Option<T> 当作普通值使用,这样能防止你意外访问 None 。
来看这个例子:
let x: i8 = 5; | |
let y: Option<i8> = Some(5); | |
let sum = x + y; // ❌ 不能直接相加! |
错误信息:
no implementation for `i8 + Option<i8>` |
Rust 不允许直接把 Option<i8> 当作 i8 ,必须先处理 Option ,确保它有值。
# 如何取出 Option<T> 的值?
你必须显式地告诉 Rust 如何处理 None ,避免程序崩溃。可以用 match 语句来处理:
fn plus_one(x: Option<i32>) -> Option<i32> { | |
match x { | |
Some(i) => Some(i + 1), // 有值时 +1 | |
None => None, // 没有值,返回 None | |
} | |
} | |
let five = Some(5); | |
let six = plus_one(five); //six 是 Some (6) | |
let none = plus_one(None); // 仍然是 None |
这里 match 确保了:
- 如果
x里有值(Some(i)),就加 1。 - 如果
x是None,就保持None,避免出错。
# 数组
两种数组:第一种是速度快但是长度固定的 array,一种是可动态增长的 Vector(动态数组)
这两个跟 & str 和 String 很像
数组的三要素:
长度固定
元素必须有相同的类型
依次线性排列
数组越界会直接报错
数组的赋值:
let a = [i32:from(4),3];//let a:[i32;3]=[4,4,4]; | |
[ | |
4, | |
4, | |
4, | |
] |
这里仅限于基础类型,如果是复杂类型
就得这样写:
let array = [String::from("rust is good!"),String::from("rust is good!"),String::from("rust is good!")]; | |
println!("{:#?}", array); |
也可以调用 std::array::from_fn
let array:[String;8] = std::array::from_fn(|_i| String::from("rust is good!")); | |
println!("{:#?}",array); | |
[ | |
"rust is good!", | |
"rust is good!", | |
"rust is good!", | |
"rust is good!", | |
"rust is good!", | |
"rust is good!", | |
"rust is good!", | |
"rust is good!", | |
] |
# 数组切片:
let a: [i32; 5] = [1, 2, 3, 4, 5]; | |
let slice: &[i32] = &a[1..3]; | |
assert_eq!(slice, &[2, 3]); |
前面的复习代码:
// use num::complex::Complex; | |
#[derive(Debug)] | |
enum PokerSuit { | |
Clubs, | |
Spades, | |
Diamonds, | |
Hearts, | |
} | |
fn add(i:i32,j:i32)->i32{ | |
i+j | |
} | |
fn calculate_length(s : &String)->usize{ | |
s.len() | |
} | |
fn huoyong(a_aa : &mut String){ | |
a_aa.push_str(",nizhidaode") | |
} | |
fn print_suit(card: PokerSuit) { | |
// 需要在定义 enum PokerSuit 的上面添加上 #[derive (Debug)],否则会报 card 没有实现 Debug | |
println!("{:?}",card); | |
} | |
struct User{ | |
active: bool, | |
username: String, | |
email: String, | |
sign_in_count: u64, | |
} | |
fn main() { | |
// let a = Complex { re: 2.1, im: -1.2 }; | |
// let b = Complex::new(11.1, 22.2); | |
// let result = a + b; | |
// println!("{} + {}i", result.re, result.im); | |
// println!("123"); | |
println!("123456"); | |
println!("123456"); | |
let x: i32 = 3; | |
let y ={let x =3;x+1}; | |
println!("The value o y is:{}",y); | |
println!("x + y = {}",add(x,y)); | |
let s= String::from("hello"); | |
let len = calculate_length(&s); | |
println!("{}",len); | |
let mut s1 = String::from("hello"); | |
huoyong(&mut s1); | |
println!("{}",s1); | |
let mut u = String::from("hello world"); | |
println!("{}",&u[0..5]); | |
println!("{}",&u[6..11]); | |
u.push_str("life"); | |
let string_replace = String::from("I like rust. Learning rust is my favorite!"); | |
let new_string_replace = string_replace.replace("rust", "RUST"); | |
dbg!(new_string_replace); | |
let mut string_replace_range = String::from("I like rust!"); | |
string_replace_range.replace_range(7..9, "RU"); | |
dbg!(string_replace_range); | |
let byte_escape = "I'm writing \x52\x75\x73\x74!"; | |
println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape); | |
// \u 可以输出一个 unicode 字符 | |
let unicode_codepoint = "\u{211D}"; | |
let character_name = "\"DOUBLE-STRUCK CAPITAL R\""; | |
println!( | |
"Unicode character {} (U+211D) is called {}", | |
unicode_codepoint, character_name | |
); | |
// 换行了也会保持之前的字符串格式 | |
// 使用 \ 忽略换行符 | |
let long_string = "String literals | |
can span multiple lines. | |
The linebreak and indentation here ->\ | |
<- can be escaped too!"; | |
println!("{}", long_string); | |
// //let tup:(i32,f64,u8)=(500,6.4,11); | |
//// 模式匹配 | |
// let tup:(i32,f64,u8)=(500,13.5,98); | |
// let(w ,y,z)=tup; | |
//println!("这个元组中的 y 值为:{}",y); | |
// let w = tup.0; | |
//println!("这个元组中的 q 值为:{}",w); | |
let user1 = User{ | |
email:String::from("aaaa@qq.com"), | |
username:String::from("odiws"), | |
active:true, | |
sign_in_count:1, | |
}; | |
println!("结构体是{}",user1.active); | |
let heart = PokerSuit::Hearts; | |
let diamond = PokerSuit::Diamonds; | |
print_suit(heart); | |
print_suit(diamond); | |
} |
# 流程控制
语法:
if condition==true{ | |
//A... | |
}else{ | |
//B... | |
} |
但是 if 和 else 返回值不统一时会报错(用 if 赋值时)
if else if else if else |
# for 循环:
fn main() { | |
for i in 1..=5 { | |
println!("{}", i); | |
} | |
} |
当然,我们也需要注意循环变量的类型,关系到所有权的问题,若是简单的变量,循环之后便可以还能使用,若是这样的:
let v = vec![1, 2, 3]; | |
for item in v { // 所有权转移 | |
println!("{}", item); | |
} | |
// 这里 v 已经被 move,不能再用 |
v 便不能再用
若是加引用,便可再用(个人理解是去了地址,而不是直接取代这个变量):
let v = vec![1, 2, 3]; | |
for item in &v { // 不可变借用 | |
println!("{}", item); | |
} | |
// 这里 v 还能继续用 |
可变借用一样的:
let mut v = vec![1, 2, 3]; | |
for item in &mut v { | |
*item += 1; | |
} |
# while 循环:
while condition{
主体
}
# loop 循环:
loop{ | |
得加条件,break,不然一直跑,cpu得干炸 | |
} |
# 模式匹配
# match 模板语法:
match target { | |
模式1 => 表达式1, | |
模式2 => { | |
语句1; | |
语句2; | |
表达式2 | |
}, | |
_ => 表达式3 | |
} |
实例:
enum Direction { | |
East, | |
West, | |
North, | |
South, | |
} | |
enum Coin{ | |
Penny, | |
Nickel, | |
Dime, | |
Quarter, | |
} | |
fn value_in_cents(coin:Coin)->u8{ | |
match coin { | |
Coin::Penny => { | |
println!("Lucky penny"); | |
1 | |
}, | |
Coin::Nickel=>5, | |
Coin::Dime=>10, | |
Coin::Quarter=>25, | |
} | |
} | |
fn main() { | |
let dire = Direction::South; | |
match dire { | |
Direction::East => println!("East"), | |
Direction::North | Direction::South => { | |
println!("South or North"); | |
}, | |
_ => println!("West"), | |
}; | |
let aaa=Coin::Penny; | |
println!("value = {}",value_in_cents(aaa)); | |
} |
还有一点很重要,match 本身也是一个表达式,因此可以用它来赋值:
enum IpAddr{ | |
enum IpAddr { | |
Ipv4, | |
Ipv6 | |
} | |
fn main() { | |
let ip1 = IpAddr::Ipv6; | |
let ip_str = match ip1 { | |
IpAddr::Ipv4 => "127.0.0.1", | |
_ => "::1", | |
}; | |
println!("{}", ip_str); | |
} | |
} |
更复杂的例子:
enum Action { | |
Say(String), | |
MoveTo(i32, i32), | |
ChangeColorRGB(u16, u16, u16), | |
} | |
fn main() { | |
let actions = [ | |
Action::Say("Hello Rust".to_string()), | |
Action::MoveTo(1,2), | |
Action::ChangeColorRGB(255,255,0), | |
]; | |
for action in actions { | |
match action { | |
Action::Say(s) => { | |
println!("{}", s); | |
}, | |
Action::MoveTo(x, y) => { | |
println!("point from (0, 0) move to ({}, {})", x, y); | |
}, | |
Action::ChangeColorRGB(r, g, _) => { | |
println!("change color into '(r:{}, g:{}, b:0)', 'b' has been ignored", | |
r, g, | |
); | |
} | |
} | |
} | |
} |
可以看出来_是可以忽略变量输出的
# 注意:这个模式匹配作用域中对外部变量的修改是在改作用域中奏效,但是出去之后就作废了
# 结构 option:
option 枚举:在枚举中,我们知道他是用来解决 rust 中变量是否有值的问题
enum Option>T>{ | |
None, | |
Some(T), | |
} |
简单解释就是:一个变量要么优质:Some(T)要么就是控制 None
fn plus_one(x: Option<i32>) -> Option<i32> { | |
match x { | |
None => None, | |
Some(i) => Some(i + 1), | |
} | |
} | |
let five = Some(5); | |
let six = plus_one(five); | |
let none = plus_one(None); |
这个函数是为了获取一个 Option 的 x 变量,返回 Option 这个 enum,模式匹配一下返回若是 None 就返回 None,是 Some(i)就返回 Some(i+1)
# 模式:
# match 分支:
match VALUE { | |
PATTERN => EXPRESSION, | |
PATTERN => EXPRESSION, | |
PATTERN => EXPRESSION, | |
} |
可以用_来匹配余下的情况,因为这是穷尽式的,尽量所有的情况都有,不然会警告
# if let 分支
if let 往往用于匹配一个模式,而忽略剩下的所有模式的场景:
if let PATTERN = SOME_VALUE { | |
} |
# while let 条件循环
一个与 if let 类似的结构是 while let 条件循环,它允许只要模式匹配就一直进行 while 循环。下面展示了一个使用 while let 的例子:
// Vec 是动态数组 | |
let mut stack = Vec::new(); | |
// 向数组尾部插入元素 | |
stack.push(1); | |
stack.push(2); | |
stack.push(3); | |
//stack.pop 从数组尾部弹出元素 | |
while let Some(top) = stack.pop() { | |
println!("{}", top); | |
} |
这个例子会打印出 3 、 2 接着是 1 。 pop 方法取出动态数组的最后一个元素并返回 Some(value) ,如果动态数组是空的,将返回 None ,对于 while 来说,只要 pop 返回 Some 就会一直不停的循环。一旦其返回 None , while 循环停止。我们可以使用 while let 来弹出栈中的每一个元素。
你也可以用 loop + if let 或者 match 来实现这个功能,但是会更加啰嗦。
# for 循环
let v = vec!['a', 'b', 'c']; | |
for (index, value) in v.iter().enumerate() { | |
println!("{} is at index {}", value, index); | |
} |
这里使用 enumerate 方法产生一个迭代器,该迭代器每次迭代会返回一个 (索引,值) 形式的元组,然后用 (index,value) 来匹配。
# let 语句
let PATTERN = EXPRESSION; |
是的, 该语句我们已经用了无数次了,它也是一种模式匹配:
let x = 5; |
这其中, x 也是一种模式绑定,代表将匹配的值绑定到变量 x 上。因此,在 Rust 中,变量名也是一种模式,只不过它比较朴素很不起眼罢了。
let (x, y, z) = (1, 2, 3); |
上面将一个元组与模式进行匹配(模式和值的类型必需相同!),然后把 1, 2, 3 分别绑定到 x, y, z 上。
模式匹配要求两边的类型必须相同,否则就会导致下面的报错:
let (x, y) = (1, 2, 3); | |
error[E0308]: mismatched types | |
--> src/main.rs:4:5 | |
| | |
4 | let (x, y) = (1, 2, 3); | |
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})` | |
| | | |
| expected a tuple with 3 elements, found one with 2 elements | |
| | |
= note: expected tuple `({integer}, {integer}, {integer})` | |
found tuple `(_, _)` | |
For more information about this error, try `rustc --explain E0308`. | |
error: could not compile `playground` due to previous error |
对于元组来说,元素个数也是类型的一部分!
# 函数参数
函数参数也是模式:
fn foo(x: i32) { | |
// 代码 | |
} |
其中 x 就是一个模式,你还可以在参数中匹配元组:
fn print_coordinates(&(x, y): &(i32, i32)) { | |
println!("Current location: ({}, {})", x, y); | |
} | |
fn main() { | |
let point = (3, 5); | |
print_coordinates(&point); | |
} |
&(3, 5) 会匹配模式 &(x, y) ,因此 x 得到了 3 , y 得到了 5 。
# let 和 if let
对于以下代码,编译器会报错:
let Some(x) = some_option_value; |
因为右边的值可能不为 Some ,而是 None ,这种时候就不能进行匹配,也就是上面的代码遗漏了 None 的匹配。
类似 let , for 和 match 都必须要求完全覆盖匹配,才能通过编译 (不可驳模式匹配)。
但是对于 if let ,就可以这样使用:
if let Some(x) = some_option_value { | |
println!("{}", x); | |
} |
因为 if let 允许匹配一种模式,而忽略其余的模式 (可驳模式匹配)。
# let-else (Rust 1.65 新增)
使用 let-else 匹配,即可使 let 变为可驳模式。它可以使用 else 分支来处理模式不匹配的情况,但是 else 分支中必须用发散的代码块处理(例如: break 、 return 、 panic )。请看下面的代码:
use std::str::FromStr; | |
fn get_count_item(s: &str) -> (u64, &str) { | |
let mut it = s.split(' '); | |
let (Some(count_str), Some(item)) = (it.next(), it.next()) else { | |
panic!("Can't segment count item pair: '{s}'"); | |
}; | |
let Ok(count) = u64::from_str(count_str) else { | |
panic!("Can't parse integer: '{count_str}'"); | |
}; | |
// error: `else` clause of `let...else` does not diverge | |
// let Ok(count) = u64::from_str(count_str) else { 0 }; | |
(count, item) | |
} | |
fn main() { | |
assert_eq!(get_count_item("3 chairs"), (3, "chairs")); | |
} |
与 match 和 if let 相比, let-else 的一个显著特点在于其解包成功时所创建的变量具有更广的作用域。在 let-else 语句中,成功匹配后的变量不再仅限于特定分支内使用:
// if let | |
if let Some(x) = some_option_value { | |
println!("{}", x); | |
} | |
// let-else | |
let Some(x) = some_option_value else { return; } | |
println!("{}", x); |
在上面的例子中, if let 写法里的 x 只能在 if 分支内使用,而 let-else 写法里的 x 则可以在 let 之外使用。
# 解构结构体:
let p = Point { x: 0, y: 7 }; | |
let Point { x: a, y: b } = p; | |
assert_eq!(0, a); | |
assert_eq!(7, b); |
这段代码创建了变量 a 和 b 来匹配结构体 p 中的 x 和 y 字段,这个例子展示了模式中的变量名不必与结构体中的字段名一致。不过通常希望变量名与字段名一致以便于理解变量来自于哪些字段。
可以直接省略这个 a 跟 b,这样直接就是将 x 赋值为 Point 的 x 的值,y 同理
# 解构枚举:
下面代码以 Message 枚举为例,编写一个 match 使用模式解构每一个内部值:
enum Message { | |
Quit, | |
Move { x: i32, y: i32 }, | |
Write(String), | |
ChangeColor(i32, i32, i32), | |
} | |
fn main() { | |
let msg = Message::ChangeColor(0, 160, 255); | |
match msg { | |
Message::Quit => { | |
println!("The Quit variant has no data to destructure.") | |
} | |
Message::Move { x, y } => { | |
println!( | |
"Move in the x direction {} and in the y direction {}", | |
x, | |
y | |
); | |
} | |
Message::Write(text) => println!("Text message: {}", text), | |
Message::ChangeColor(r, g, b) => { | |
println!( | |
"Change the color to red {}, green {}, and blue {}", | |
r, | |
g, | |
b | |
) | |
} | |
} | |
}Change the color to red 0, green 160, and blue 255 |
这里老生常谈一句话,模式匹配一样要类型相同,因此匹配 Message::Move{1,2} 这样的枚举值,就必须要用 Message::Move{x,y} 这样的同类型模式才行。
这段代码会打印出 Change the color to red 0, green 160, and blue 255 。尝试改变 msg 的值来观察其他分支代码的运行。
对于像 Message::Quit 这样没有任何数据的枚举成员,不能进一步解构其值。只能匹配其字面值 Message::Quit ,因此模式中没有任何变量。
对于另外两个枚举成员,就用相同类型的模式去匹配出对应的值即可。
# 解构嵌套的结构体和枚举:
metch 也可以进行嵌套:
例如使用下面的代码来同时支持 RGB 和 HSV 色彩模式:
enum Color { | |
Rgb(i32, i32, i32), | |
Hsv(i32, i32, i32), | |
} | |
enum Message { | |
Quit, | |
Move { x: i32, y: i32 }, | |
Write(String), | |
ChangeColor(Color), | |
} | |
fn main() { | |
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255)); | |
match msg { | |
Message::ChangeColor(Color::Rgb(r, g, b)) => { | |
println!( | |
"Change the color to red {}, green {}, and blue {}", | |
r, | |
g, | |
b | |
) | |
} | |
Message::ChangeColor(Color::Hsv(h, s, v)) => { | |
println!( | |
"Change the color to hue {}, saturation {}, and value {}", | |
h, | |
s, | |
v | |
) | |
} | |
_ => () | |
} | |
} |
match 第一个分支的模式匹配一个 Message::ChangeColor 枚举成员,该枚举成员又包含了一个 Color::Rgb 的枚举成员,最终绑定了 3 个内部的 i32 值。第二个,就交给亲爱的读者来思考完成。
# 解构结构体和元组:
我们甚至可以用复杂的方式来混合,匹配和嵌套解构模式,如下是一个复杂结构体的例子,其中结构体和元组嵌套在元组中,并将所有的原始类型解构出来:
struct Point{ | |
x:i32, | |
y:i32, | |
} | |
let ((feet,inches),Point {x,y})=((3,10),Point{x:3,y:-10}); |
# 解构数组:
对于数组我们可以用类似于元组的方式解构:
# 定长数组:
let arr: [u16; 2] = [114, 514]; | |
let [x, y] = arr; | |
assert_eq!(x, 114); | |
assert_eq!(y, 514); |
# 不定长数组:
语法:let arr:&[数据类型] = &[114,514];
取值为 & 114
let arr: &[u16] = &[114, 514]; | |
if let [x, ..] = arr { | |
assert_eq!(x, &114); | |
} | |
if let &[.., y] = arr { | |
assert_eq!(y, 514); | |
} | |
let arr: &[u16] = &[]; | |
assert!(matches!(arr, [..])); | |
assert!(!matches!(arr, [x, ..])); |
# 忽略模式中的值:_
match 中的最后一个分支使用_模式匹配所有剩余的值,我们也可以在另一个模式中使用_模式。使用一个以下划线开始的名称,或者使用.. 忽略所剩部分的值。
# 使用 _ 忽略整个值
虽然 _ 模式作为 match 表达式最后的分支特别有用,但是它的作用还不限于此。例如可以将其用于函数参数中:
fn foo(_: i32, y: i32) { | |
println!("This code only uses the y parameter: {}", y); | |
} | |
fn main() { | |
foo(3, 4); | |
} |
这段代码会完全忽略作为第一个参数传递的值 3 ,并会打印出 This code only uses the y parameter: 4 。
大部分情况当你不再需要特定函数参数时,最好修改签名不再包含无用的参数。在一些情况下忽略函数参数会变得特别有用,比如实现特征时,当你需要特定类型签名但是函数实现并不需要某个参数时。此时编译器就不会警告说存在未使用的函数参数,就跟使用命名参数一样。
# 使用嵌套的 _ 忽略部分值
可以在一个模式内部使用 _ 忽略部分值:
let mut setting_value = Some(5); | |
let new_setting_value = Some(10); | |
match (setting_value, new_setting_value) { | |
(Some(_), Some(_)) => { | |
println!("Can't overwrite an existing customized value"); | |
} | |
_ => { | |
setting_value = new_setting_value; | |
} | |
} | |
println!("setting is {:?}", setting_value); |
这段代码会打印出 Can't overwrite an existing customized value 接着是 setting is Some(5) 。
第一个匹配分支,我们不关心里面的值,只关心元组中两个元素的类型,因此对于 Some 中的值,直接进行忽略。 剩下的形如 (Some(_),None) , (None, Some(_)) , (None,None) 形式,都由第二个分支 _ 进行分配。
还可以在一个模式中的多处使用下划线来忽略特定值,如下所示,这里忽略了一个五元元组中的第二和第四个值:
let numbers = (2, 4, 8, 16, 32); | |
match numbers { | |
(first, _, third, _, fifth) => { | |
println!("Some numbers: {}, {}, {}", first, third, fifth) | |
}, | |
} |
老生常谈:模式匹配一定要类型相同,因此匹配 numbers 元组的模式,也必须有五个值(元组中元素的数量也属于元组类型的一部分)。
这会打印出 Some numbers: 2, 8, 32 , 值 4 和 16 会被忽略。
# 使用下划线开头忽略未使用的变量
如果创建了一个变量却不在任何地方使用它,rust 通常会给你一个警告,因为这可能是一个 bug。但是又是创建一个不会被使用的变量是有用的,比如你正在设计原型或者刚刚开始一个项目,这是你希望告诉 Rust 不要警告未使用的变量,为此可以用下划线作为变量名的开头:
fn main() { | |
let _x = 5; | |
let y = 10; | |
} |
这里得到了警告说未使用变量 y ,至于 x 则没有警告。
注意,只使用 _ 和使用以下划线开头的名称有些微妙的不同:比如 _x 仍会将值绑定到变量,而 _ 则完全不会绑定。
let s = Some(String::from("Hello!")); | |
if let Some(_s) = s { | |
println!("found a string"); | |
} | |
println!("{:?}", s); |
s 是一个拥有所有权的动态字符串,在上面代码中,我们会得到一个错误,因为 s 的值会被转移给 _s ,在 println! 中再次使用 s 会报错:
error[E0382]: borrow of partially moved value: `s`
--> src/main.rs:8:22
|
4 | if let Some(_s) = s {
| -- value partially moved here
...
8 | println!("{:?}", s);
| ^ value borrowed here after partial move
只使用下划线本身,则并不会绑定值,因为 s 没有被移动进 _ :
let s = Some(String::from("Hello!")); | |
if let Some(_) = s { | |
println!("found a string"); | |
} | |
println!("{:?}", s); |
# 用.. 忽略剩余值
对于有多个部分的值,可以使用 .. 语法来只使用部分值而忽略其它值,这样也不用再为每一个被忽略的值都单独列出下划线。 .. 模式会忽略模式中剩余的任何没有显式匹配的值部分。
struct Point { | |
x: i32, | |
y: i32, | |
z: i32, | |
} | |
let origin = Point { x: 0, y: 0, z: 0 }; | |
match origin { | |
Point { x, .. } => println!("x is {}", x), | |
} |
这里列出了 x 值,接着使用了 .. 模式来忽略其它字段,这样的写法要比一一列出其它字段,然后用 _ 忽略简洁的多。
还可以用 .. 来忽略元组中间的某些值:
fn main() { | |
let numbers = (2, 4, 8, 16, 32); | |
match numbers { | |
(first, .., last) => { | |
println!("Some numbers: {}, {}", first, last); | |
}, | |
} | |
} |
这里用 first 和 last 来匹配第一个和最后一个值。 .. 将匹配并忽略中间的所有值。
然而使用 .. 必须是无歧义的。如果期望匹配和忽略的值是不明确的,Rust 会报错。下面代码展示了一个带有歧义的 .. 例子,因此不能编译:
fn main() { | |
let numbers = (2, 4, 8, 16, 32); | |
match numbers { | |
(.., second, ..) => { | |
println!("Some numbers: {}", second) | |
}, | |
} | |
} |
如果编译上面的例子,会得到下面的错误:
error: `..` can only be used once per tuple pattern // 每个元组模式只能使用一个 `..` | |
--> src/main.rs:5:22 | |
| | |
5 | (.., second, ..) => { | |
| -- ^^ can only be used once per tuple pattern | |
| | | |
| previously used here // 上一次使用在这里 | |
error: could not compile `world_hello` due to previous error ^^ |
Rust 无法判断, second 应该匹配 numbers 中的第几个元素,因此这里使用两个 .. 模式,是有很大歧义的!
# 匹配守卫提供的额外条件:
它是一个位于 match 分支模式之后的额外 if 条件,它能为分支模式提供更进一步的匹配条件
这个条件可以使用模式中创建的变量:
let num = Some(4); | |
match num { | |
Some(x) if x < 5 => println!("less than five: {}", x), | |
Some(x) => println!("{}", x), | |
None => (), | |
} |
less than five: 4 |
这个例子会打印出 less than five: 4 。当 num 与模式中第一个分支匹配时, Some(4) 可以与 Some(x) 匹配,接着匹配守卫检查 x 值是否小于 5,因为 4 小于 5,所以第一个分支被选择。
相反如果 num 为 Some(10) ,因为 10 不小于 5 ,所以第一个分支的匹配守卫为假。接着 Rust 会前往第二个分支,因为这里没有匹配守卫所以会匹配任何 Some 成员。
模式中无法提供类如 if x < 5 的表达能力,我们可以通过匹配守卫的方式来实现。
# @绑定:
@ (读作 at)运算符允许为一个字段绑定另外一个变量。下面例子中,我们希望测试 Message::Hello 的 id 字段是否位于 3..=7 范围内,同时也希望能将其值绑定到 id_variable 变量中以便此分支中相关的代码可以使用它。我们可以将 id_variable 命名为 id ,与字段同名,不过出于示例的目的这里选择了不同的名称。
enum Message { | |
Hello { id: i32 }, | |
} | |
let msg = Message::Hello { id: 5 }; | |
match msg { | |
Message::Hello { id: id_variable @ 3..=7 } => { | |
println!("Found an id in range: {}", id_variable) | |
}, | |
Message::Hello { id: 10..=12 } => { | |
println!("Found an id in another range") | |
}, | |
Message::Hello { id } => { | |
println!("Found some other id: {}", id) | |
}, | |
} | |
Found an id in range: 5 |
上例会打印出 Found an id in range: 5 。通过在 3..=7 之前指定 id_variable @ ,我们捕获了任何匹配此范围的值并同时将该值绑定到变量 id_variable 上。
第二个分支只在模式中指定了一个范围, id 字段的值可以是 10、11 或 12 ,不过这个模式的代码并不知情也不能使用 id 字段中的值,因为没有将 id 值保存进一个变量。
最后一个分支指定了一个没有范围的变量,此时确实拥有可以用于分支代码的变量 id ,因为这里使用了结构体字段简写语法。不过此分支中没有像头两个分支那样对 id 字段的值进行测试:任何值都会匹配此分支。
当你既想要限定分支范围,又想要使用分支的变量时,就可以用 @ 来绑定到一个新的变量上,实现想要的功能。
# @前绑定后解构 (Rust 1.56 新增)
使用 @ 还可以在绑定新变量的同时,对目标进行解构:
#[derive(Debug)] | |
struct Point { | |
x: i32, | |
y: i32, | |
} | |
fn main() { | |
// 绑定新变量 `p`,同时对 `Point` 进行解构 | |
let p @ Point {x: px, y: py } = Point {x: 10, y: 23}; | |
println!("x: {}, y: {}", px, py); | |
println!("{:?}", p); | |
let point = Point {x: 10, y: 5}; | |
if let p @ Point {x: 10, y} = point { | |
println!("x is 10 and y is {} in {:?}", y, p); | |
} else { | |
println!("x was not 10 :("); | |
} | |
} |
# 方法 Method
方法定义:
Rust 使用 impl 了定义方法,例如以下代码:
struct Circle { | |
x: f64, | |
y: f64, | |
radius: f64, | |
} | |
impl Circle { | |
//new 是 Circle 的关联函数,因为它的第一个参数不是 self,且 new 并不是关键字 | |
// 这种方法往往用于初始化当前结构体的实例 | |
fn new(x: f64, y: f64, radius: f64) -> Circle { | |
Circle { | |
x: x, | |
y: y, | |
radius: radius, | |
} | |
} | |
// Circle 的方法,&self 表示借用当前的 Circle 结构体 | |
fn area(&self) -> f64 { | |
std::f64::consts::PI * (self.radius * self.radius) | |
} | |
} |
这个是 rust 与其他面对对象编程语言的区别:
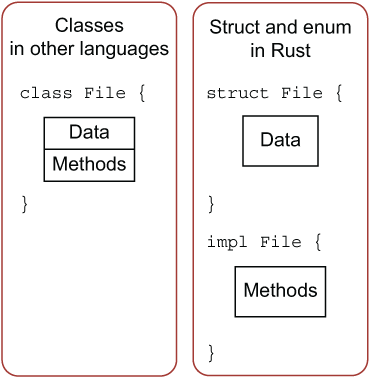
可以看出,其它语言中所有定义都在 class 中,但是 Rust 的对象定义和方法定义是分离的,这种数据和使用分离的方式,会给予使用者极高的灵活度。
# self、&self 和 &mut self
接下来的内容非常重要,请大家仔细看。在 area 的签名中,我们使用 &self 替代 rectangle: &Rectangle , &self 其实是 self: &Self 的简写(注意大小写)。在一个 impl 块内, Self 指代被实现方法的结构体类型, self 指代此类型的实例,换句话说, self 指代的是 Rectangle 结构体实例,这样的写法会让我们的代码简洁很多,而且非常便于理解:我们为哪个结构体实现方法,那么 self 就是指代哪个结构体的实例。
需要注意的是, self 依然有所有权的概念:
self表示Rectangle的所有权转移到该方法中,这种形式用的较少&self表示该方法对Rectangle的不可变借用&mut self表示可变借用
总之, self 的使用就跟函数参数一样,要严格遵守 Rust 的所有权规则。
回到上面的例子中,选择 &self 的理由跟在函数中使用 &Rectangle 是相同的:我们并不想获取所有权,也无需去改变它,只是希望能够读取结构体中的数据。如果想要在方法中去改变当前的结构体,需要将第一个参数改为 &mut self 。仅仅通过使用 self 作为第一个参数来使方法获取实例的所有权是很少见的,这种使用方式往往用于把当前的对象转成另外一个对象时使用,转换完后,就不再关注之前的对象,且可以防止对之前对象的误调用。
简单总结下,使用方法代替函数有以下好处:
-
不用在函数签名中重复书写
self对应的类型 -
代码的组织性和内聚性更强,对于代码维护和阅读来说,好处巨大
等于就是第一个是什么也动不了,第二个就是可读,第三个就是可以进行修改
# 方法名跟结构体字段名相同
在 Rust 中,允许方法名跟结构体的字段名相同:
impl Rectangle { | |
fn width(&self) -> bool { | |
self.width > 0 | |
} | |
} | |
fn main() { | |
let rect1 = Rectangle { | |
width: 30, | |
height: 50, | |
}; | |
if rect1.width() { | |
println!("The rectangle has a nonzero width; it is {}", rect1.width); | |
} | |
} |
当我们使用 rect1.width() 时,Rust 知道我们调用的是它的方法,如果使用 rect1.width ,则是访问它的字段。
一般来说,方法跟字段同名,往往适用于实现 getter 访问器,例如:
mod my { | |
pub struct Rectangle { | |
width: u32, | |
pub height: u32, | |
} | |
impl Rectangle { | |
pub fn new(width: u32, height: u32) -> Self { | |
Rectangle { width, height } | |
} | |
pub fn width(&self) -> u32 { | |
return self.width; | |
} | |
pub fn height(&self) -> u32 { | |
return self.height; | |
} | |
} | |
} | |
fn main() { | |
let rect1 = my::Rectangle::new(30, 50); | |
println!("{}", rect1.width()); // OK | |
println!("{}", rect1.height()); // OK | |
// println!("{}", rect1.width); // Error - the visibility of field defaults to private | |
println!("{}", rect1.height); // OK | |
} |
当从模块外部访问结构体时,结构体的字段默认是私有的,其目的是隐藏信息(封装)。我们如果想要从模块外部获取 Rectangle 的字段,只需把它的 new , width 和 height 方法设置为公开可见,那么用户就可以创建一个矩形,同时通过访问器 rect1.width() 和 rect1.height() 方法来获取矩形的宽度和高度。
因为 width 字段是私有的,当用户访问 rect1.width 字段时,就会报错。注意在此例中, Self 指代的就是被实现方法的结构体 Rectangle 。
特别的是,这种默认的可见性(私有的)可以通过 pub 进行覆盖,这样对于模块外部来说,就可以直接访问使用 pub 修饰的字段而无需通过访问器。这种可见性仅当从定义结构的模块外部访问时才重要,并且具有隐藏信息(封装)的目的。
# 关于运算符去哪了?
# -> 运算符到哪去了?
在 C/C++ 语言中,有两个不同的运算符来调用方法: . 直接在对象上调用方法,而 -> 在一个对象的指针上调用方法,这时需要先解引用指针。换句话说,如果 object 是一个指针,那么 object->something() 和 (*object).something() 是一样的。
Rust 并没有一个与 -> 等效的运算符;相反,Rust 有一个叫 自动引用和解引用的功能。方法调用是 Rust 中少数几个拥有这种行为的地方。
他是这样工作的:当使用 object.something() 调用方法时,Rust 会自动为 object 添加 & (视可见性添加 &mut )、 * 以便使 object 与方法签名匹配。也就是说,这些代码是等价的:
p1.distance(&p2); | |
(&p1).distance(&p2); |
第一行看起来简洁的多。这种自动引用的行为之所以有效,是因为方法有一个明确的接收者 ———— self 的类型。在给出接收者和方法名的前提下,Rust 可以明确地计算出方法是仅仅读取( &self ),做出修改( &mut self )或者是获取所有权( self )。事实上,Rust 对方法接收者的隐式借用让所有权在实践中更友好。
# 带有多个参数的方法:
fn can_hold(&self, other: &Rectangle) -> bool { | |
self.width > other.width && self.height > other.height | |
} |
# 关联函数(类似与 java 里面的构造函数):
在 impl 中且没有 self 函数的被称之为关联函数,因为他没有 self,不能用 f.read () 的形式调用,因此它是一个函数而不是方法,他又在 impl 中,与结构体紧密关联,因此称为关联函数。
impl Rectangle{ | |
fn new(w:u32,h:i32)->Rectangle{ | |
Rectangle{width:w,height:h} | |
} | |
} |
因为是函数,所以不能用。的方式来调用,我们需要用::来调用,例如 let sq=Rectangle::new (3,3); 这个方法位于结构体的命名空间中::: 语法用于关联函数和模块创建的命名空间。
# 多个 impl 定义:
Rust 允许我们为一个结构体定义多个 impl 块,目的是提供更多的灵活性和代码组织性,例如当方法多了后,可以把相关的方法组织在同一个 impl 块中,那么就可以形成多个 impl 块,各自完成一块儿目标:
struct Rectangle { | |
width: u32, | |
height: u32, | |
} | |
// 第一个 impl 块:专注于与矩形的基本信息相关的方法 | |
impl Rectangle { | |
fn new(width: u32, height: u32) -> Self { | |
Rectangle { width, height } | |
} | |
fn area(&self) -> u32 { | |
self.width * self.height | |
} | |
fn perimeter(&self) -> u32 { | |
2 * (self.width + self.height) | |
} | |
} | |
// 第二个 impl 块:专注于与矩形的可变性相关的方法 | |
impl Rectangle { | |
fn resize(&mut self, width: u32, height: u32) { | |
self.width = width; | |
self.height = height; | |
} | |
} | |
// 第三个 impl 块:为 Rectangle 实现其他自定义方法 | |
impl Rectangle { | |
fn description(&self) -> String { | |
format!("Rectangle with width {} and height {}", self.width, self.height) | |
} | |
} | |
fn main() { | |
let mut rect = Rectangle::new(10, 5); | |
// 计算面积和周长 | |
println!("Area: {}", rect.area()); | |
println!("Perimeter: {}", rect.perimeter()); | |
// 更改矩形的尺寸 | |
rect.resize(20, 10); | |
println!("Updated: {}", rect.description()); | |
} |
# 为枚举实现方法:
枚举类型之所以强大,不仅仅在于它好用,可以同一化类型,还在于我们可以像结构体一样,为枚举实现方法:
#![allow(unused)] | |
enum Message { | |
Quit, | |
Move { x: i32, y: i32 }, | |
Write(String), | |
ChangeColor(i32, i32, i32), | |
} | |
impl Message { | |
fn call(&self) { | |
// 在这里定义方法体 | |
} | |
} | |
fn main() { | |
let m = Message::Write(String::from("hello")); | |
m.call(); | |
} |
除了结构体和枚举,我们还能为特征 (trait) 实现方法,这将在下一章进行讲解,在此之前,先来看看泛型。
# 泛型和特征
# 泛型 Generics
需求:用同一功能的函数处理不同类型的数据,例如两个数的加法,无论是整数还是浮点数,甚至是自定义类型,都能进行支持。在不支持泛型的编程语言中,通常需要为每一种类型编写一个函数:
fn add_i8(a:i8, b:i8) -> i8 { | |
a + b | |
} | |
fn add_i32(a:i32, b:i32) -> i32 { | |
a + b | |
} | |
fn add_f64(a:f64, b:f64) -> f64 { | |
a + b | |
} | |
fn main() { | |
println!("add i8: {}", add_i8(2i8, 3i8)); | |
println!("add i32: {}", add_i32(20, 30)); | |
println!("add f64: {}", add_f64(1.23, 1.23)); | |
} |
上述的代码可以运行,但是可扩展性差,我们需要寻求一个方式去解决这个问题
多态便是一个类对一件事情能做出不一样的反应(java 的说法),实际上,泛型就是一种多态,泛型的目的就是为了程序员解放双手,减少代码量
fn add<T>(a:T, b:T) -> T { | |
a + b | |
} | |
fn main() { | |
println!("add i8: {}", add(2i8, 3i8)); | |
println!("add i32: {}", add(20, 30)); | |
println!("add f64: {}", add(1.23, 1.23)); | |
} |
上面代码的 T 就是泛型参数,实际上在 Rust 中,泛型参数的名称可以任意起,一般用的是 T 来作为首选,一个字母最完美;使用泛型参数有一个先决条件,必须在使用前对其进行声明:
fn largest<T>(list: &[T]) -> T{}
&表示这是一个 引用,不会获取所有权。[T]表示这是一个 连续的元素序列,元素类型为T。
这里可以遍历获取返回最大值
现在是错误的泛型函数实现:
fn largest<T>(list: &[T]) -> T { | |
let mut largest = list[0]; | |
for &item in list.iter() { | |
if item > largest { | |
largest = item; | |
} | |
} | |
largest | |
} | |
fn main() { | |
let number_list = vec![34, 50, 25, 100, 65]; | |
let result = largest(&number_list); | |
println!("The largest number is {}", result); | |
let char_list = vec!['y', 'm', 'a', 'q']; | |
let result = largest(&char_list); | |
println!("The largest char is {}", result); | |
} |
运行发现报错:
error[E0369]: binary operation `>` cannot be applied to type `T` // `>`操作符不能用于类型`T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- T
| |
| T
|
help: consider restricting type parameter `T` // 考虑对T进行类型上的限制 :
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> T {
| ++++++++++++++++++++++
发现是 T 的类型范围太大造成的错误
编译器给的建议是加上 std::cmp::PartialOrd 特征(Trait)对 T 进行限制
,该特征的目的就是让类型实现课比较的功能。
# 显式地指定泛型的类型参数
有时候,编译器无法推断你想要的泛型参数:
use std::fmt::Display; | |
fn create_and_print<T>() where T: From<i32> + Display { | |
let a: T = 100.into(); // 创建了类型为 T 的变量 a,它的初始值由 100 转换而来 | |
println!("a is: {}", a); | |
} | |
fn main() { | |
create_and_print(); | |
} |
如果运行以上代码,会得到报错:
error[E0283]: type annotations needed // 需要标明类型
--> src/main.rs:9:5
|
9 | create_and_print();
| ^^^^^^^^^^^^^^^^ cannot infer type of the type parameter `T` declared on the function `create_and_print` // 无法推断函数 `create_and_print` 的类型参数 `T` 的类型
|
= note: multiple `impl`s satisfying `_: From<i32>` found in the `core` crate:
- impl From<i32> for AtomicI32;
- impl From<i32> for f64;
- impl From<i32> for i128;
- impl From<i32> for i64;
note: required by a bound in `create_and_print`
--> src/main.rs:3:35
|
3 | fn create_and_print<T>() where T: From<i32> + Display {
| ^^^^^^^^^ required by this bound in `create_and_print`
help: consider specifying the generic argument // 尝试指定泛型参数
|
9 | create_and_print::<T>();
| +++++
报错里说得很清楚,编译器不知道 T 到底应该是什么类型。不过好心的编译器已经帮我们列出了满足条件的类型,然后告诉我们解决方法:显式指定类型: create_and_print::<T>() 。
于是,我们修改代码:
use std::fmt::Display; | |
fn create_and_print<T>() where T: From<i32> + Display { | |
let a: T = 100.into(); // 创建了类型为 T 的变量 a,它的初始值由 100 转换而来 | |
println!("a is: {}", a); | |
} | |
fn main() { | |
create_and_print::<i64>(); | |
}a is: 100 |
即可成功运行。
这个就是在 create_and_print::<> 这个尖括号里面加上 i64 数据类型,这样就是显性告诉编译器 T 应该是 i64 类型
# 100.into() 示例
假设你有一个整数 100 ,并且你想将它转换成另一种类型。例如,你想将 100 从 i32 转换为 f64 。
let x: f64 = 100.into(); // 将 100 从 i32 转换为 f64 | |
println!("{}", x); // 输出: 100.0 |
# 结构体中使用泛型:
结构体中的字段类型也可以用泛型来定义,下面的代码定义了一个坐标点 Point,它可以存放任何类型的坐标值:
struct Point<T> {
x:T,
y:T,
}
fn main(){
let integer = Point{x:5,y:10};
let float = Point{x:1.0,y:4.0};
}
# 枚举中使用泛型:
enum Option<T> { | |
Some(T), | |
None, | |
} |
这个泛型是一个拥有泛型 T 的枚举类型,他第一个成员是 Some(T),存放了一个类型为 T 的值,。
得益于泛型的引入 ,我们可以在任何一个需要返回值的函数中,去使用 Option<T> 枚举类型来做为返回值,用于返回一个任意类型的值 Some(T)
enum Result<T, E> { | |
Ok(T), | |
Err(E), | |
} |
这个枚举跟 Option 一样,主要用于函数返回值,与 Option 用于值得存在与否不同,Result 关注的是值的正确性。
如果函数正常运行返回 Ok (T)异常时返回 Err (E) 例如打开一个文件:如果成功打开文件,则返回 Ok(std::fs::File) ,因此 T 对应的是 std::fs::File 类型;而当打开文件时出现问题时,返回 Err(std::io::Error) , E 对应的就是 std::io::Error 类型。
# 方法中使用泛型
https://course.rs/basic/trait/generic.html#const - 泛型 rust-151 - 版本引入的重要特性